Creating interactive digital environments for gaming, robotics, and simulation relies on articulated 3D objects whose functionality emerges from their part geometry and kinematic structure. However, existing approaches remain fundamentally limited: optimization-based reconstruction methods require slow, per-object joint fitting and typically handle only simple, single-joint objects, while retrieval-based methods assemble parts from a fixed library, leading to repetitive geometry and poor generalization. To address these challenges, we introduce ArtLLM, a novel framework for generating high-quality articulated assets directly from complete 3D meshes. At its core is a 3D multimodal large language model trained on a large-scale articulation dataset curated from both existing articulation datasets and procedurally generated objects. Unlike prior work, ArtLLM autoregressively predicts a variable number of parts and joints, inferring their kinematic structure in a unified manner from the object's point cloud. This articulation-aware layout then conditions a 3D generative model to synthesize high-fidelity part geometries. Experiments on the PartNet-Mobility dataset show that ArtLLM significantly outperforms state-of-the-art methods in both part layout accuracy and joint prediction, while generalizing robustly to real-world objects. Finally, we demonstrate its utility in constructing digital twins, highlighting its potential for scalable robot learning.
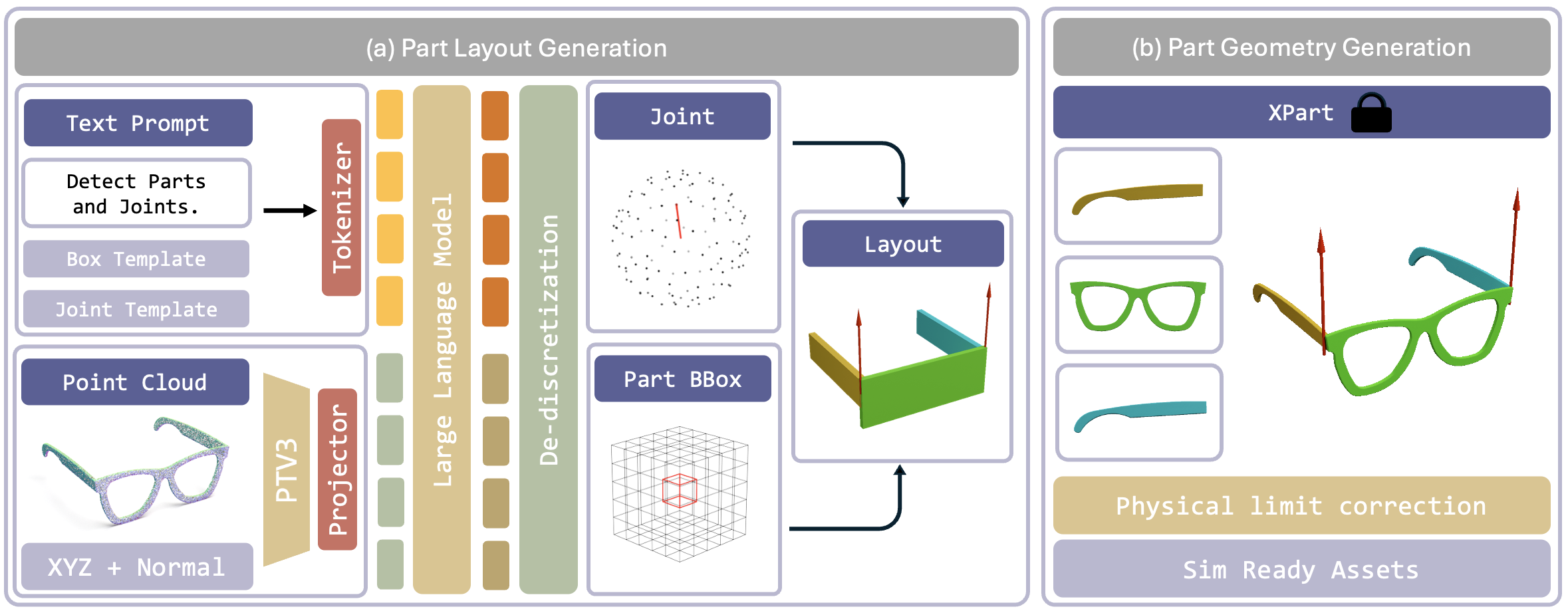
Given an input point cloud, ArtLLM first predicts a tokenized articulation blueprint that specifies part layouts and kinematic structures. This blueprint then conditions a part-aware generative model to synthesize high-fidelity link geometries, followed by a physics-based joint-limit correction module refines the articulation, producing simulation-ready articulated assets.
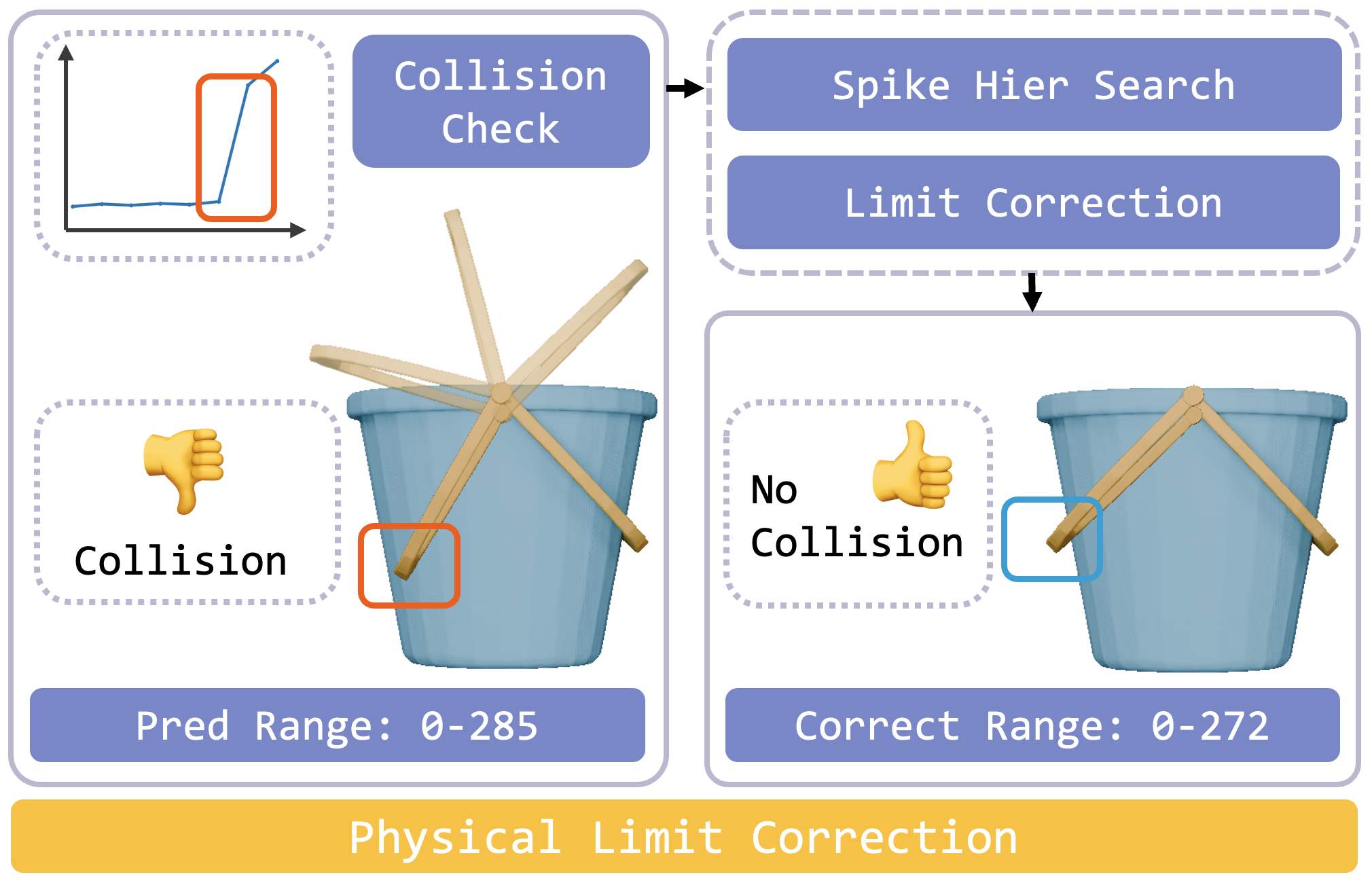
When predicting joint limits, the model relies solely on the geometric state at a single timestep, which limits its abil ity to perceive dynamic motion. This can lead to inter-part collisions during articulation, thereby compromising phys ical realism. To address this issue, we introduce a post processing correction step that refines joint limits based on collision detection.
@inproceedings{wang2026artllm,
title={ArtLLM: Generating Articulated Assets via 3D LLM},
author={Wang, Penghao and Xie, Siyuan and Yan, Hongyu and Yang, Xianghui and Huang, Jingwei and Guo, Chunchao and Gu, Jiayuan},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={34281--34291},
year={2026}
}