
We present V^3, a novel method that can stream 2D Gridded Gaussians to mobiles for high-quality rendering with low storage requirements, providing users with a unique volumetric video viewing experience across multiple devices.
Overview Video
Representation
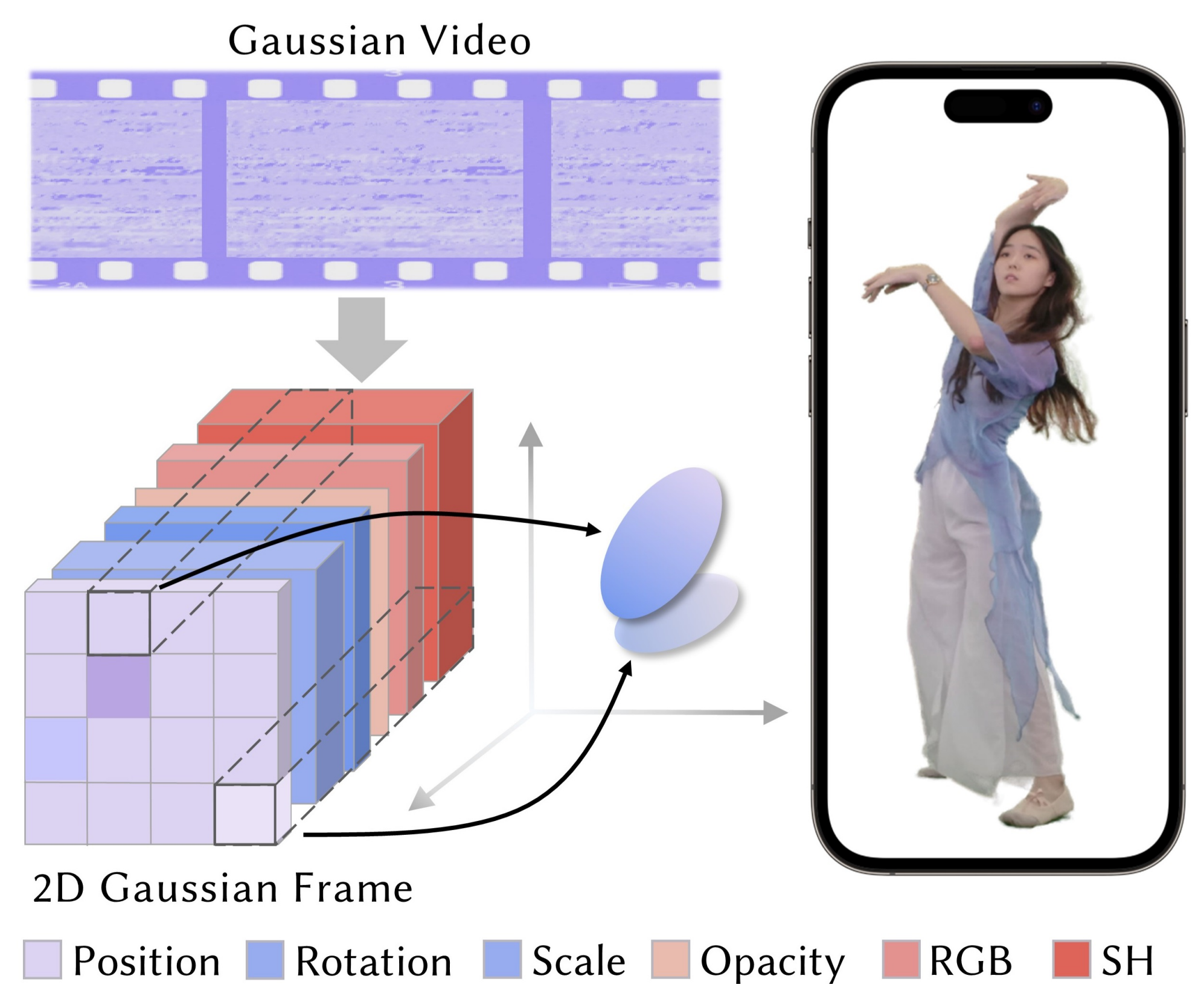
We model dynamic 3DGS as a 2D video with multiple dimensions, where each frame corresponds to its specific 3DGS attributes. During the rendering, we extract Gaussian properties from each pixel to recover Gaussian Splat structural.
Method
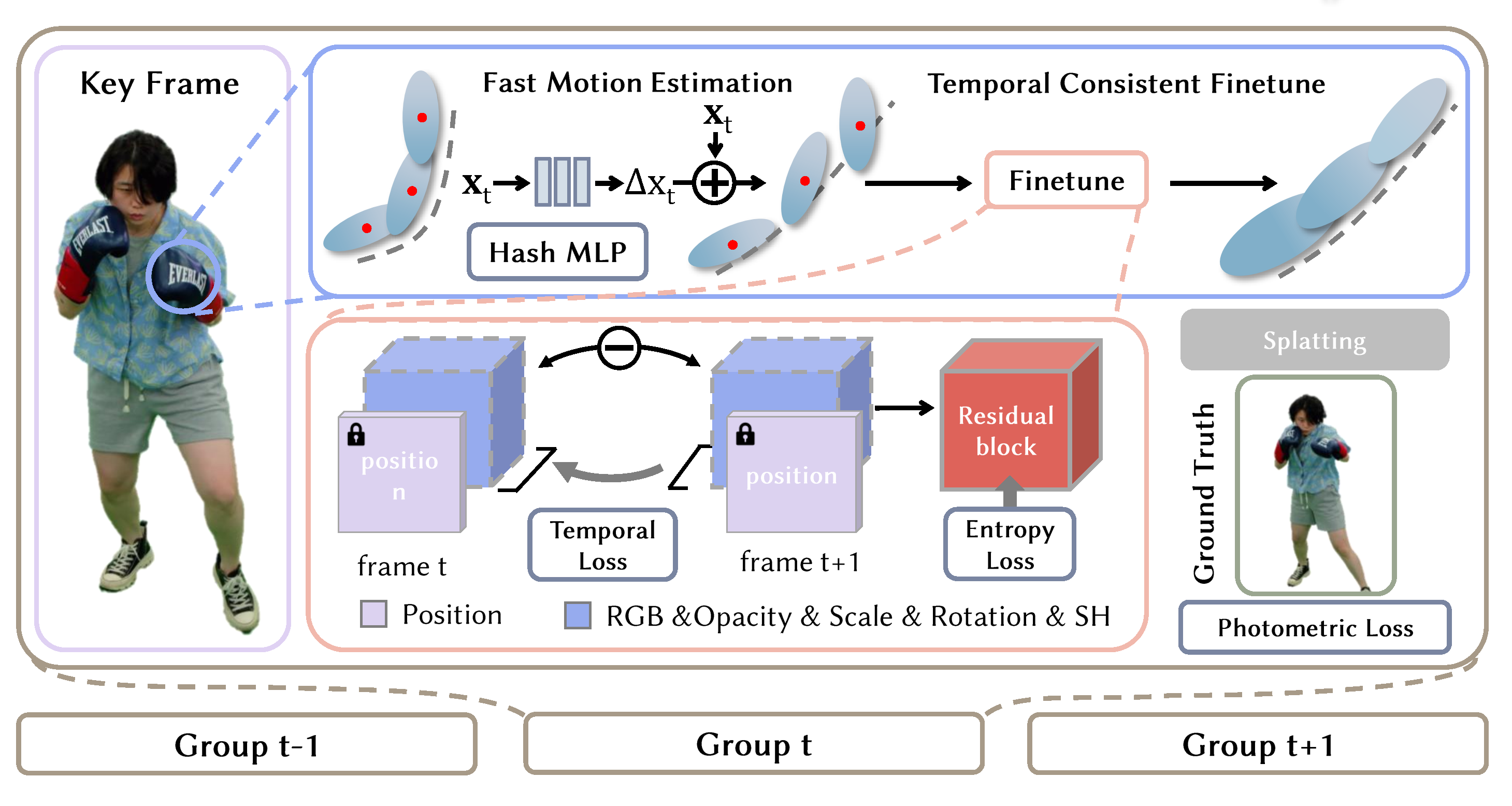
First, we divide the long sequences into groups for training. In the first stage, we use hash encoding following a shallow MLP with position as input to estimate the motion of the human subjects. In the second stage, we fine-tune the attributes of the wrapped Gaussians from stage 1 with residual entropy loss and temporal loss, which yields 2D Gaussian video with highly temporal consistency and thus can use video codec to perform efficient compression.
Comparison

Qualitative Comparison against recent SOTA methods including VideoRF [Wang et al. 2024], 3DGStream [Sun et al. 2024], HumanRF [Işık et al. 2023],NeuS2 [Wang et al. 2023a]. Our method achieves high-quality rendering with clear details.
Result Gallery

Gallery of our results. Our method can achieve high-quality novel view synthesis in scenes with challenging motion and flexible topology changes.